Flink Checkpoint 机制
本文主要根据《Lightweight Asynchronous Snapshots for Distributed Dataflows》论文介绍 Flink 的轻量级异步快照算法。全局一致性快照是有状态分布式系统实现故障恢复机制的基础,在 Flink 中就使用了全局一致性快照机制实现系统的故障容错性(Fault tolerance),并确保有状态数据流的 Exactly-Once 语义。和已有的分布式全局快照算法相比,Flink 团队在论文中提出的异步屏障快照(Asynchronous Barrier Snapshotting/ABS)算法在系统的停顿及快照空间占用方面进行了改进,拥有更好的成本及性能。因此在 Flink 系统中,可以在计算作业运行时频繁的进行快照操作而不会对性能产生很大影响。
ABS 算法的思路来源于 Chandy-Lamport 分布式快照算法。在 Chandy-Lamport 算法中,要求下游进程负责保存指向它的消息通道的状态。而 ABS 中,它不再需要保存有向无环图的消息通道状态,而对于有向有环图,也只需额外保存少量的消息通道状态。
背景
Apache Flink 是一个批/流处理统一的分布式计算引擎。Flink 的作业(Jobs)在执行前都会被 Flink 编译为一个有向任务图(directed graphs of tasks ),我们以 G = (T, E) 代表这个有向图,其中图的顶点 T 代表任务,边 E 代表任务间的数据通道。任务所需的数据从外部数据源中获取,并以 pipeline 的方式在任务图中路由传递执行。任务根据收到的输入数据持续地计算更新其内部状态,并生成新的输出。更进一步的,任务可以区分为 source 任务(没有输入数据通道)以及 sink 任务(没有输出数据通道)。每个任务都是一个 flink operator 实例的封装(比如 Flink DataStreams 支持 map/filter/reduce 等 operator),并且可以通过将 operator 实例并行放置数据流的不同分区将 operator 并行化,从而使得流的 transformation 操作可以分布式的执行。
假设 M 代表的是任务并行执行是所传输的一系列记录(records),每个任务 t ∈ T 封装的独立执行的 operator 实例由如下部分组成:1、一系列输入/输出管道 I_t,O_t ⊆ E;2、一个 operator 状态 s_t 以及;3、一个用户自定义函数(UDF)f_t。数据的摄入都是基于 pull 方式的:每个任务在执行时,消费输入记录,更新自己的 operator 状态,并根据 UDF 的执行结果产生新的记录输出。更具体一点来说,对于每个记录 r ∈ M,由任务 t ∈ T 接收,并根据其 UDF 定义 f_ : s_t,r → ⟨s_t′,D⟩,产生一个新的状态 s_t′ 及一系列新的输出记录 D ⊆ M。
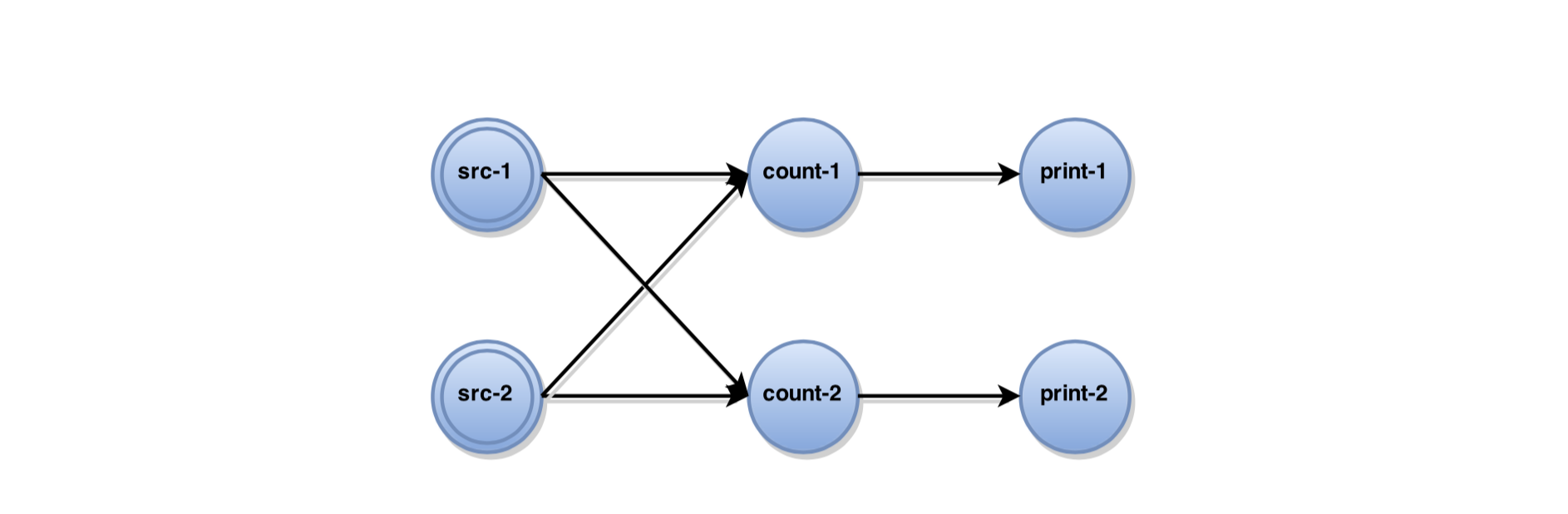
如图 1 为 Apache Flink 中增量统计字符个数的简单示例,在这个例子中单词从文本中读入,做一个简单累加后由 print 输出到标准输出。这是一个有状态的流服务,因为输入节点需要注意当前文件的读取位置以及统计节点需要维护一个当前字符数统计值作为它的内部状态。
异步屏障快照
我们定义 G* = (T* , E* ) 为运行图 G = (T, E) 的全局快照,其中 T* 由所有 operator 的状态组成 st∗ ∈ T∗,∀t ∈ T,E* 由所有的通道状态组成 e∗ ∈ E∗,其中 e* 就是通道 e 上正在传输的所有记录。
我们要求每个快照 G* 都具有某些属性(如可终止性和可行性),以保证在恢复后结果的正确性。
可终止性确保了在所有进程都存活的状态下快照可以在启动后的有限时间内完成,可行性代表了快照的意义,即在快照过程中,不会丢失任何有关计算的信息。
无环图的 ABS 算法
当我们把执行过程切分为多个阶段时,无需保留数据通道的状态做快照的情况就是有可能的。各阶段切分了输入的数据流和相关的计算,每个阶段之前的输入输出都已经完全处理完成,因此在阶段结束时各个 operator 的状态就是整个执行的历史,因此它就可以拿来用作快照。
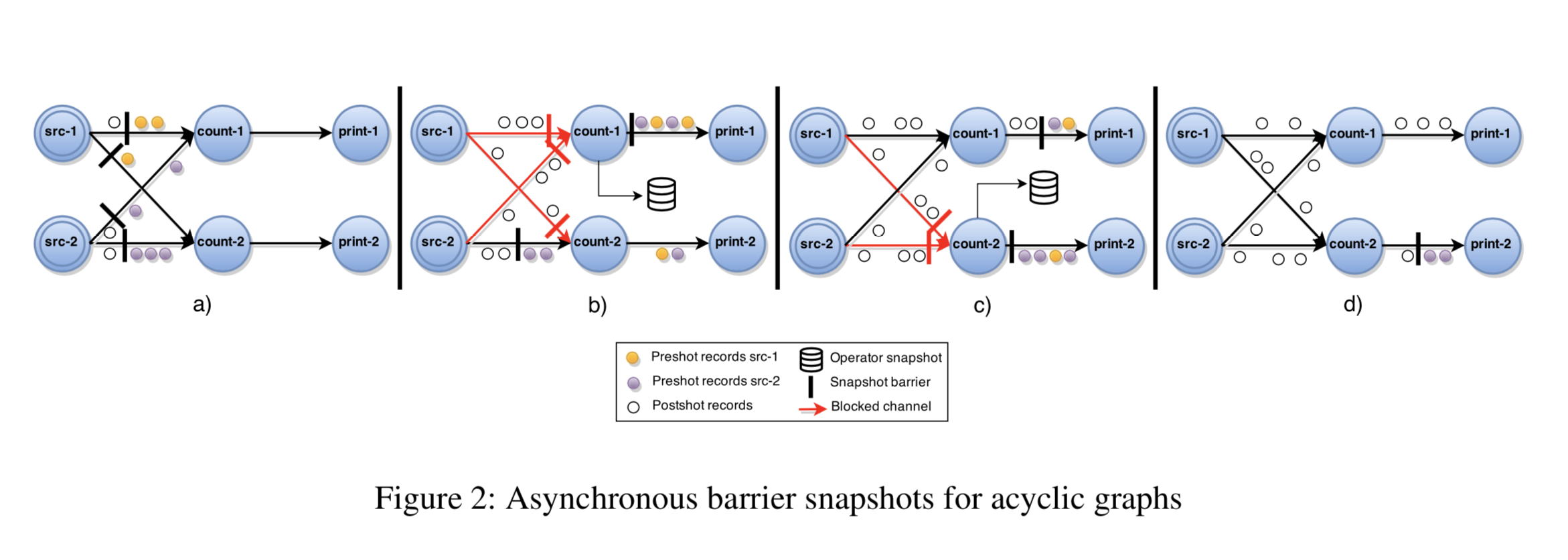
在我们的方法中,阶段模拟以以下方式实现:在持续的输入数据流中,我们周期性的插入一些特殊的 barrier 标志,这些 barrier 标志顺着任务执行图会一直传递到 sink 输出节点。全局快照即增量的由各个任务接收到这些 barrier 标志后进行快照操作组合而成。我们再进一步的给我们的算法定义一些假设:
- 网络通道是可靠的,遵循 FIFO 顺序,并可以被阻塞及放开阻塞。当一个通道被阻塞时,所有的消息都需要被缓存,直到阻塞被放开。
- 任务可以在它们的通道组件上触发阻塞、放开阻塞及发送消息等操作,并且也支持广播消息到所有的输出通道。
- source 任务中的注入消息(即 barrier)的通道解析为“Nil/无”。
无环图 ABS 算法的具体执行流程如下:一个中央协调器定期的向所有 source 注入阶段 barrier 标志。当一个 source 接收到 barrier 之后,它首先给自己当前的状态做一个快照,然后将 barrier 广播给所有的输出通道(图 2a))。当一个非 source 的任务从它的某个输入通道接收到 barrier 之后,它需要阻塞住这个通道,并等待它的所有输入通道的 barrier 都接收到为止(图 2b))(注:barrier 对齐过程)。当所有的输入通道 barrier 都接收到了,这个任务首先将 barrier 广播给所有的输出通道,再给自己当前的状态打一个快照(图 2c))。接着,这个任务放开输入通道的阻塞,并继续进行任务的处理(图 2d))。所有的 operator 状态 T* 将组合成为一个完整的全局状态快照 G* = (T* , E* ) ,这里的 E* = 0 (为空)。
有环图的 ABS 算法
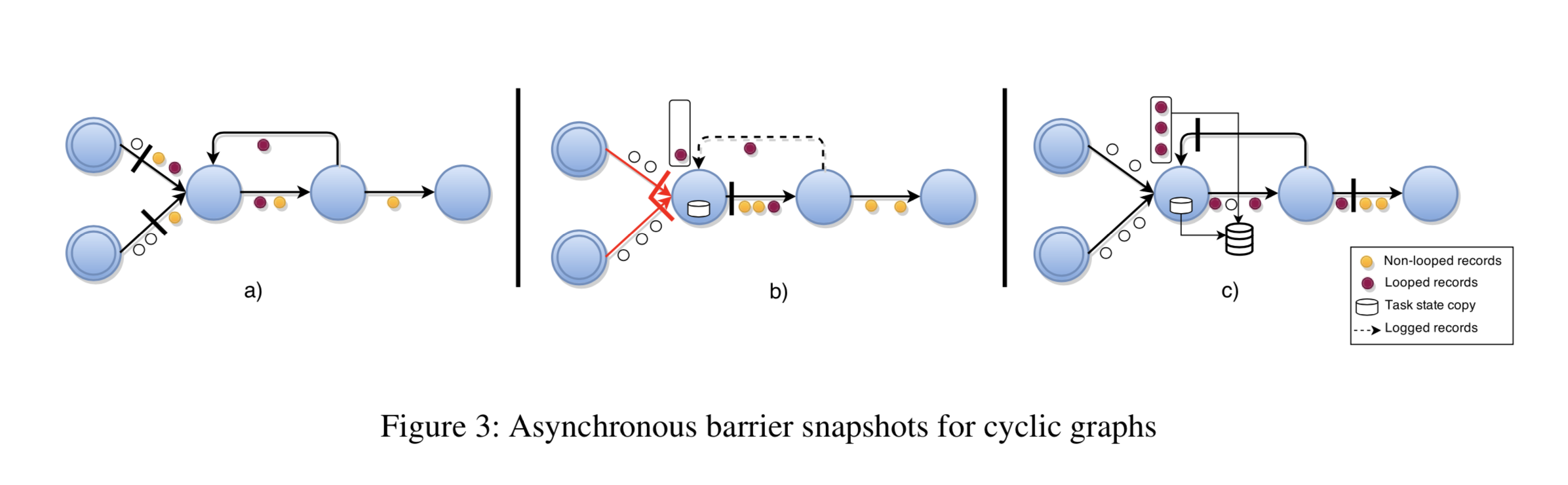
在执行图有环的情况下前面介绍的 ABS 算法将不可行,等待所有输入通道 barrier 时会陷入死锁,并且环中的数据也无法保存至快照中,而出于一致性要求这些数据必须需要保存并在恢复时将其放回至环通道中。因此我们在之前的基础方法上做了扩展:首先,我们通过静态分析任务执行图识别出环的边 back-edges L,根据控制流图理论,有向图中的 back-edges 是指向深度优先搜索中已被访问的顶点的边。执行图 G(T,E\L) 是拓扑中包含所有任务的有向无环图(DAG)(?),从 DAG 的角度看,算法和之前介绍的一样执行。额外的,我们增加一个在快照过程中,下游节点协助存储已识别的 back-edges 通道的消息状态的过程。这由每个从 back-edges Lt ⊆ It,Lt 消费的任务 t 完成,t 创建所有从 Lt 接收到的记录的备份,从它发出 barrier 开始那一瞬间,持续到它再次从 Lt 接收到这个 barrier 为止。barrier 将所有在环中的记录都推了出来,并进行了记录,因此保证了快照中数据的一致性。
有环图 ABS 算法的具体执行流程如下:拥有 back-edges 输入的任务节点在接收到所有常规输入管道的 barrier 后首先建立一个当前状态的本地备份(图 3b)),然后,从这个点开始,它们记录所有从 back-edges 发送过来的记录,直到从 back-edges 收到阶段的 barrier 为止(图 3c))。这样使得环中传输的所有记录都会包含在快照当中。这样最终的全局快照 G∗ = (T∗,L∗) 包含所有的任务阶段状态 T* 及只有 back-edges 里传输的记录 L∗ ⊂ E∗。
故障恢复过程
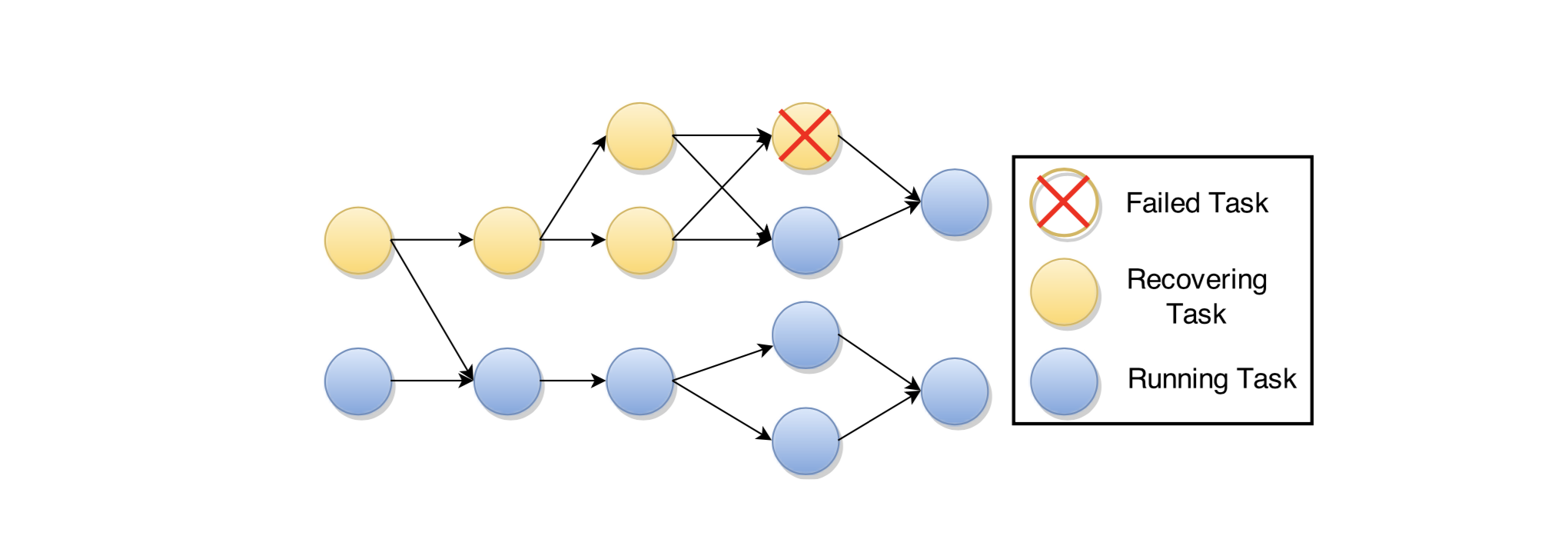
从全局一致性快照中恢复的方法有好几种,最简单的是整个执行流程从最新的全局状态中恢复(一个节点故障,整个执行图都重新恢复)。1、各个任务从持久存储的快照中获取的自身的最新状态,并设为初始状态,2、恢复备份日志(环的数据)并处理所包含的所有记录,3、从输入通道中开始拉取数据。
另外只是部分恢复图中节点的方法也是有可能的。通过整理上游任务依赖(只要有输出到故障节点的所有节点),一直到 source 节点为止,然后重新恢复这部分节点(如图 4)。为了保证 Exactly-Once 语义,下游节点在收到重复的消息记录时需要能够避免重复计算,为实现这个功能,我们可以参考 SDGs(参见原文参考文献 [5])的做法,在 source 节点给所有的记录都标记上一个序列号。这样,下游节点可以忽略所有序列号比它已经处理过的记录小的消息。
(注:结合 ABS 恢复流程一起来看,ABS 算法一个未显式提出的要求是需要数据源能够支持数据回溯(比如大家比较熟悉的 Kafka 支持消费者 offset 回溯功能)。Flink 的 source 节点只保留了数据源的消费 offset,如果数据源不支持根据 offset 进行回溯,则无法实现 ABS 的故障恢复要求。)
实现
Flink 中使用了 ABS 确保流计算运行时的 Exactly-Once 语义。在我们当前实现中所有被阻塞队列的记录都被保存在了磁盘上以增加系统的鲁棒性,当然这样也一定程度上增加了 ABS 对运行时的影响。
为了区分 operator 状态数据和普通数据,我们提供了一个单独的 OperatorState 接口用以创建和更新 operator 状态。我们为基于 offset 的数据源和聚合提供了有状态 operator 的 OperatorState 实现。
快照的协作机制在 Flink 的 JobManager 中实现为一个 actor 进程,它为每个作业的执行图保存了全局快照。协作者定期的向执行图的所有 source 节点插入阶段 barrier。当发生重配置时,在分布式内存持久化存储中的最新全局快照用于operator 状态恢复。
性能评估
略。
后续工作
略。
参考资料:
[1]. Lightweight Asynchronous Snapshots for Distributed Dataflows
[2]. flink超越Spark的Checkpoint机制. https://cloud.tencent.com/developer/article/1189624
[3]. Apache Flink轻量级异步快照机制源码分析. https://yq.aliyun.com/articles/622185